I read about this awesome process called Markov Chains in this blog, it was really great how an engineer apply this concept to create unique and memorable ID's using no-meaning words.
Before this change, the unique IDs was difficult to read and memorize, but using Markov Chains, the software can generate memorable IDs using phonetics and almost familiar words related to the language. In that case, the choosen language was Japanese.
I recommend that you read that blog, it's so funny and makes a great story telling from the problem through the solution.
After that fantastic application, i decided to mimic that behavior in a service i was creating.
Maybe i will put a link after i create a blog about that service.
How it works Markov Chains
Markov Chains according to Wikipedia is:
Is a stochastic process describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event.
So what this can be related to create unique words. Imagine if you have the power to know with certain probability, what a person can say, if only just have the beginning of a word.
Well, I understand that Markov Chains can tell you which letter would have more probable after certain letter.
For example, if you say a word that starts with "a", then the markov chain can tell you which letter could be the next. In order to know which word comes next, Markov Chain needs to be created with content. In this case can be a list of words.
Imagine if you collect all the vast vocabulary from all the Spanish books, the Markov chain created from this words can be a great way to create unique words that haven't ever existed and also can spit an existing word.
For me, markov chains are a way to spit a possible outcome base on the current data i gave it.
But before to use it, you need to feed a Markov Chain, in these needs to be words.
My problem solved using Markov Chains
The main problem was that users need to type a code when the service is payed, so it's difficult to someone remember random numbers and letters, so I decided to search a memorable and unique IDs for clients.
The first question, as the same in the article, was:
What language do I use? My clients speak Spanish, so why not use a Spanish language to create those words.
Then, second question was:
What content do I use to feed my Markov Chain?
I decided to use the Don Quixote book, by Miguel de Cervantes. Mainly because it's in public domain world wide. And because Miguel de Cervantes write this book using old words , trying to mimic and parodies the language of medieval knights and chivalric romances.
Markov Chain implementation for the words generator
These the steps I folowed:
- Understand how a Markov Chain works, I recommend this video from Youtube.
- Obtained the Don Quixote in txt format from Project Gutenberg.
- Clean and collect words.
- Feed the Markov Chain
- Save the Markov Chain, for the next times we generate a new word.
- Generate the word
- Finish
Code implementattion
To explain better the code I plan add comments in the code, but basically the steps before mentioned was the way I built this.
| markov_chain_words_generator.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 | |
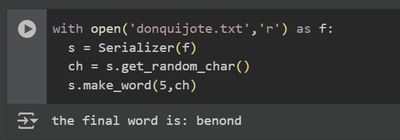
And this is how is used:
with open('donquijote.txt','r') as f:
s = Serializer(f)
ch = s.get_random_char()
s.make_word(5,ch)
Basically, the most important part is this function:
def create_markov_chain(self):
gd = {}
for cword in self.cwords:
for item in range(0,len(cword)-1):
ch_curr = cword[item]
ch_next = cword[item+1]
if ch_curr not in gd.keys():
gd[ch_curr] = dict()
gd[ch_curr][ch_next] = 1
else:
if ch_next not in gd[ch_curr]:
gd[ch_curr][ch_next] = 1
pass
else:
gd[ch_curr][ch_next] += 1
for curr_state, transition in gd.items():
total = sum(transition.values())
for ch_next, value in transition.items():
gd[curr_state][ch_next] = value/total
return gd
In order to create the Markov Chain, the process, if the pattern repeats. For example, "aba", this three words has a relation in the Markov Chain model, like this:
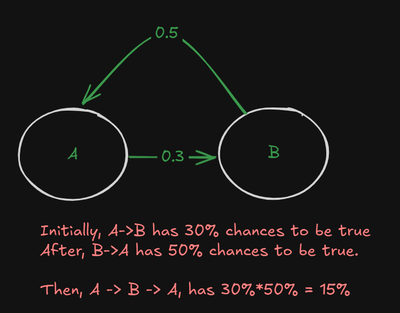
Now imagine a letter with multiples probabilities for the next letter, and these letters also has probabilities for the next letter.
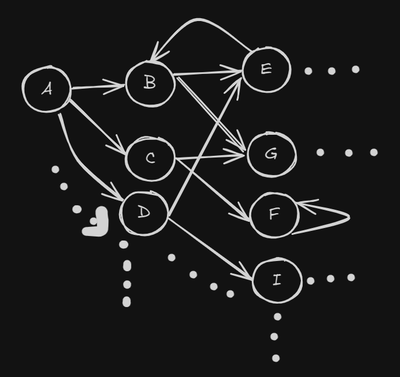
Now imagine generate a word using this Markov Chain:
You can use Google Collab to use this code, but remember use you content, in my case I use Don Quixote by Miguel de Cervantes, but you can use other content with different languages.
Conclusion
That's all, I really like to apply some knowledge in ways that even I didn't think of it. And besides I didn't implement a filter like the blog did, but besides that, I think it's a good try.
An important thing here, this unique IDs are not guarantee that after some unknown times executed, can throw the same word previously generated. But for my purpose is acceptable.